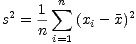
Calculating the best standard deviation estimate for small N can be tricky. First of all, calculating the sample variance s2 is reasonably straightforward
But wait, have you seen this formula with n replaced by n- 1? Ever wonder why that is? To get the so-called ”unbiased” estimate for the variance, you must use the relation
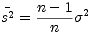
to estimate the original variance 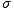 2
2
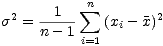
This is where the infamous n- 1 comes from. This is all well and good, but what about estimating the standard deviation? A sample standard deviation s can be defined by
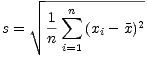
Because of the non-linearity of the square root, the mean of this distribution is not simple. Unfortunately, is also dependant of the distribution of the original process. For normally distributed random variables, it has a mean of
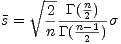
where is the actual standard deviation of the original process. To recover the
best estimate of for small n, we need to multiply our standard deviation by a
compensation factor of

In general, C(n) is not easy to calculate in a general purpose computer language, unless you have access to the Gamma function. Even if you do, the Gamma function will overflow for moderately sized n, even while C(n) is bounded.
I found a really simple way to generate a table of these values in an iterative manner. The trick was to make use of the identity
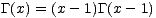
and calculate the relation
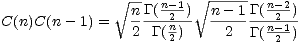
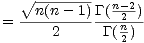
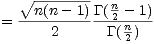
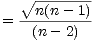
and the  ’s are gone! We simply need to start with the initial value
’s are gone! We simply need to start with the initial value
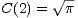
And built a table of C(n) based on the value of C(n - 1), for some reasonable range of 2 < n < nmax.
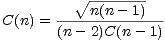
In my implementation, 32767 was plenty. The effect is only important for small n
as limn
 C(n) = 1
C(n) = 1
Now, when we need to calculate a standard deviation based on n samples, we can use
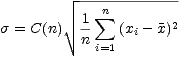
And we will have the best possible estimate, if the original random variable is normal.